AI learns when it is safer to leave a decision to a human expert
8 September 2022
Like humans, AI-systems can make mistakes. When you're shown the wrong ad, it's not such a disaster, but it gets worse when an AI system makes the wrong medical diagnosis, or your car fully automatically runs over an overlooked cyclist.
One way to make AI-applications in such high-stake tasks more reliable, is to train the AI-system to estimate both the confidence of its own decisions and the confidence of the human expert that might take over the decision. ‘If the risk of the human expert to make an error is much less than the risk of the AI making an error, then it is much better to defer the decision to the human expert’, says Rajeev Verma, who works as a master student in the Amsterdam Machine Learning Lab (AMLab) of the Informatics Institute of UvA.
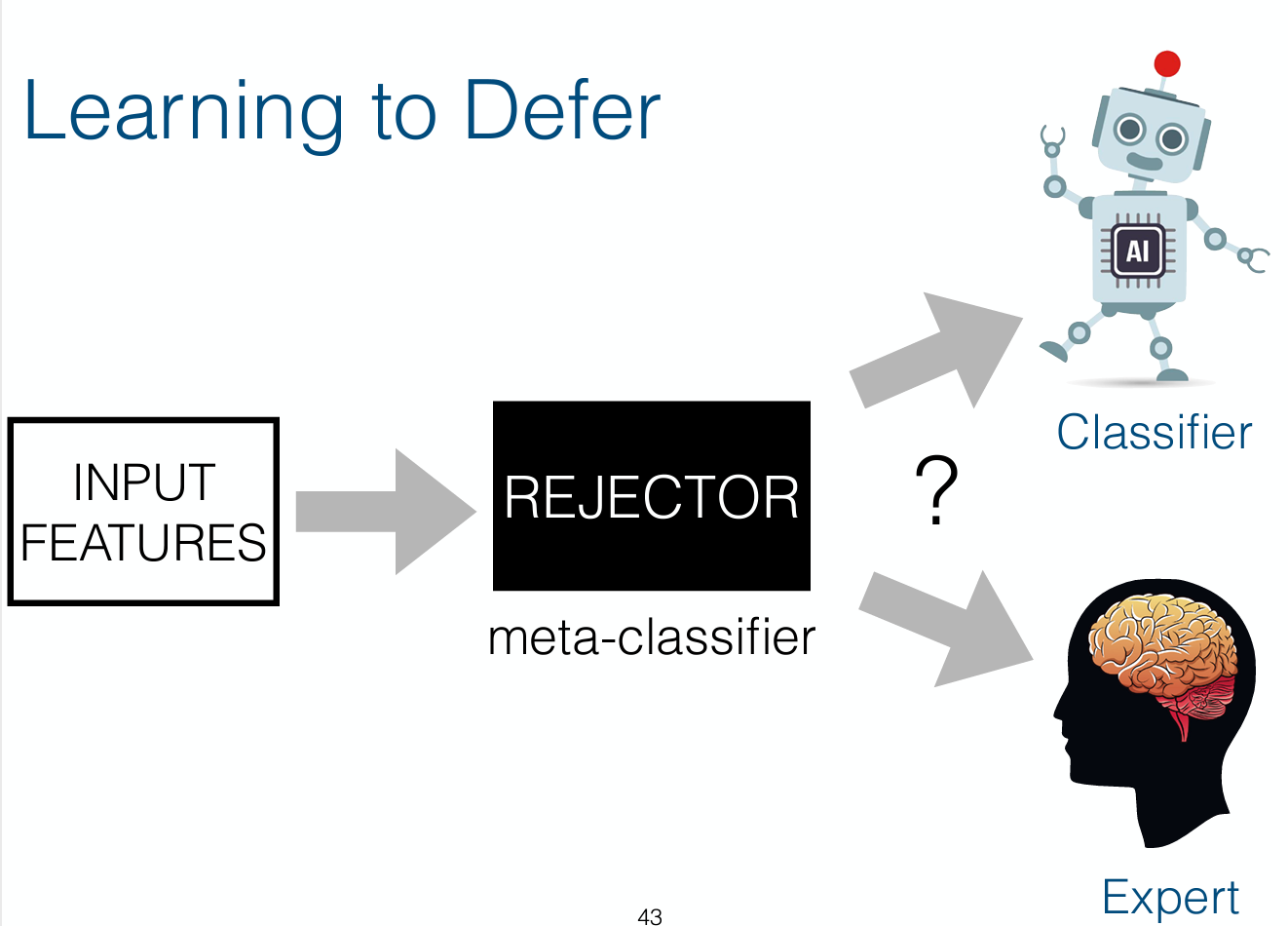
Important paradigm
Together with assistant professor of machine learning of the Informatics Institute, Eric Nalisnick, Verma developed a general framework that learns when it is safer to leave the decision to a human expert and when it is safer to leave the decision to the AI-system. ‘This is an important paradigm,’ says Nalisnick, ‘because it allows society to have gradual automation of tasks. It’s not that from one day to another we will have fully autonomous cars or fully automatic medical diagnosis. Our framework allows that humans will take some decisions, and AI-systems will take others. It tries to give the decision to the better of the two options.’
Testing
Verma and Nalisnick tested their framework in three practical settings: detecting skin lesions on the human body, detecting hate speech on social media and classifying galaxies on astronomical images. In the case of detecting skin lesions, the AI-system was trained on tens of thousands of images of lesions, with the labels given by medical experts and with the true labels (as known from a biopsy or an autopsy).
‘Our system turned out to be very good at predicting the risk that the expert, say a doctor, would make an error’, says Verma. ‘We got much better results than colleagues at MIT in previous work in this field. In most AI-applications we still have humans in the loop and our work is all meant to increase the reliability of AI-systems.’
Verma and Nalisnick presented their work this July at the International Conference on Machine Learning in Baltimore (USA).
Multiple experts
As an extension of this work, the UvA-researchers explored the case in which there is not just one human expert who can take over from the machine, but the case where there are multiple experts to choose from. Nalisnick: ‘This is, for example, very relevant in a hospital, because there are multiple doctors on call during the day. You can imagine that an AI-system could choose one particular doctor from a group of doctors, or even a subset of doctors.’
Verma and two colleagues already developed an AI-framework for deferring a decision to one expert out of a group of experts. This work was presented at the ICML 2022 Workshop on Human-Machine Collaboration and Teaming. The extension to choose a group of experts is left for future work.
‘Rajeev did all this work as part of his master thesis’, concludes Nalisnick. ‘I find it really cool that UvA-master students are able to do research at the forefront of machine learning.’
Rajeev Verma, Daniel Barrejón and Eric Nalisnick, ‘On the Calibration of Learning to Defer to Multiple Experts’, ICML 2022 Workshop on Human-Machine Collaboration and Teaming
Research information
Article Rajeev Verma and Eric Nalisnick, ‘Calibrated Learning to Defer with One-vs-All Classifiers’, Proceedings of the 39th International Conference on Machine Learning, Baltimore, Maryland, USA, PMLR 162, 2022
The research described it this article falls within the scope of the research theme 'Artificial Intelligence' of the Informatics Institute.