Adding ears to a computer counting the bounces on a trampoline
Counting repetitive phenomena by the use of sight and sound
28 June 2021
Yunhua Zhang and Cees Snoek of the Video & Image Sense Lab (VIS), in collaboration with Ling Shao from the Inception Institute of Artificial Intelligence (IIAI), developed a method for estimating how many times a certain repetitive phenomenon, such as bouncing on a trampoline, slicing an onion, or playing ping pong, happens in a video stream. Their methodology is applicable to any scenario in which repetitive motion patterns exist. By using both sight and sound, as well as their cross-modal interaction, counting predictions are shown to be much more robust than a sight-only model. The results highlight the benefits brought by the use of sound as an addition to sight, especially in harsh vision conditions, for example during low illumination, or when camera viewpoint changes, and even occlusions, where the combination of both sight and sound always outperforms the use of sight only.
The problem of bad sight
Humans are great at counting repetitions, they can filter out the irrelevant information of a video and can accurately perceive what to focus on. Computers can be trained to do so as well and can create statistics of how many times, for example, a hula hoop turns. The counting however comes with some difficulties, as the person performing the activity may move out of the camera’s field of view or the environment is too dark to see well. Previous methods, based on sight only, have a greater chance of obtaining errors in their counts, and therefore the statistics created can be less reliable. The challenging problem is getting the repetitive counting with the use of artificial intelligence as accurate as possible. To solve this problem, the researchers introduce for the first time audio signals, which are free of visual noise, into the counting process.
Repetition counting
The new model, using sound in combination with sight, proposes an intelligent repetition counting approach based on convolutional neural networks. The approach takes both the sight and audio signals as input. As the sound can indicate how the action is progressing, the model first considers both sight and sound to identify the appropriate frame rate to sample the video frames that are provided as input so that at least two repetitions are covered. Subsequently, the model recognizes what kind of motion or sound pattern is inside the video and counts how many times the pattern occurs. The more it happens, the stronger the signals that the neural network receives and the higher the counting prediction will be. By the use of a count-annotated dataset, the model can memorize what kind of repetitive motion or sound patterns exist in the world and what they look or sound like and will eventually learn how to focus on the important features of each video to count more precisely, also when perceiving patterns that it has previously not seen or heard.
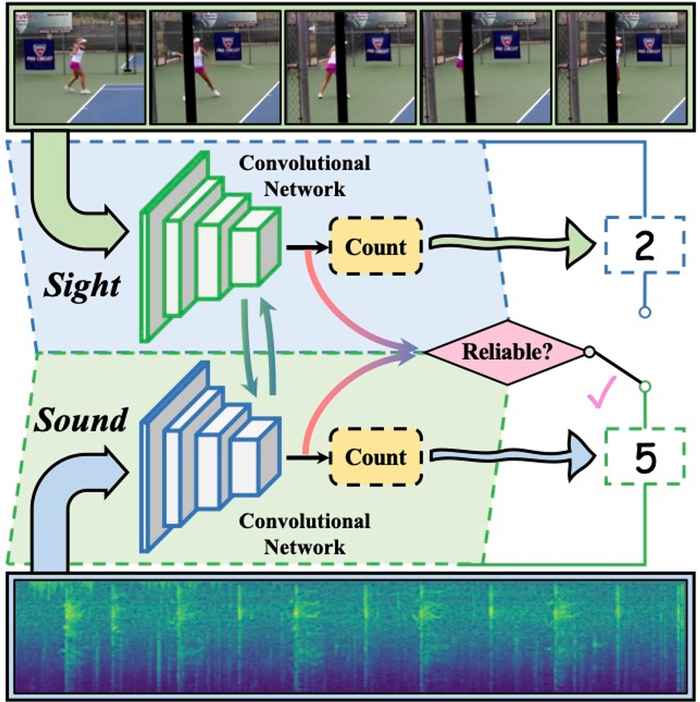
What to use: sight or sound?
Inside the model there are two streams, both streams process each modality separately to count the repetitive activity. To be specific, the sight and the sound streams take RGB images and the spectrogram of audio signals as inputs. However, the sight stream can suffer from visually challenging conditions and the audio signals may contain loud background noise. Therefore, a reliability estimation module is introduced to judge the quality of each modality and to put more trust on the counting result from the more reliable modality. Both visual and audio features extracted by the convolutional networks are sent into this module and then a reliability score is estimated to combine the counting results from both streams to obtain the final counting prediction.
Quantifying the benefits
On two new audiovisual counting datasets, experiments show that sound can play a vital role, and combining both sight and sound with cross-modal temporal interaction is always beneficial. The sight stream already outperforms the state-of-the-art by itself and the integration of sight and sound improves the result further, especially under harsh vision conditions. As seen in the video, a model combining both sight and sound always outperforms a model relying on sight only and is even more beneficial when used during poor and/or challenging sight conditions.

Video: Counting repetitive phenomena by the use of sight and sound
The video shows several videos with scale variation (breaststroke), camera viewpoint change (playing ping pong), fast motion (slicing food), a disappearing activity (playing ping pong) and low resolution (playing tennis), with the numbers in colored boxes indicating counting results and the corresponding groundtruth.